#
KoboldCpp
KoboldCpp 是一个用于 GGML 和 GGUF 模型的独立 API。
这个 VRAM Calculator by Nyx 将告诉你模型大约需要多少 RAM/VRAM。
#
Nvidia GPU Quickstart
本指南假设你使用的是 Windows。
- 下载最新版本:https://github.com/LostRuins/koboldcpp/releases
- 启动 KoboldCpp。你可能会看到 Microsoft Defender 的弹出窗口,点击
Run Anyway。 - 截至 1.58 版本,KoboldCpp 应该是这样的:
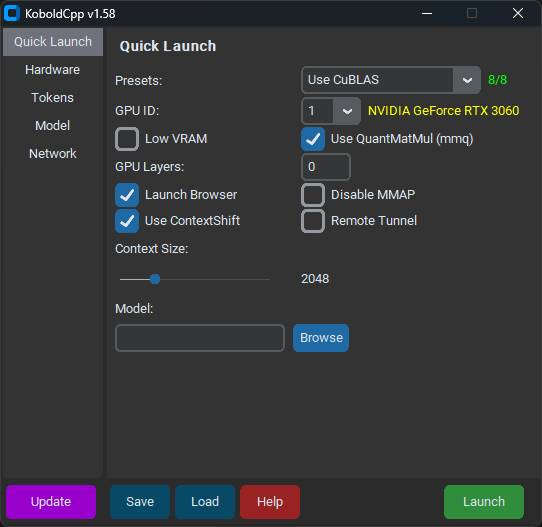
- 在
Quick Launch标签下,选择模型和你首选的Context Size。 - 选择
Use CuBLAS并确保GPU ID旁边的黄色文本与你的 GPU 匹配。 - 即使你的 VRAM 很低,也不要勾选
Low VRAM。 - 除非你使用的是 Nvidia 10 系列或更旧的 GPU,否则取消勾选
Use QuantMatMul (mmq)。 - 当你加载模型时,
GPU Layers应该已经填充。暂时保持不变。 - 在
Hardware标签下,勾选High Priority。 - 点击
Save,这样你就不必在每次启动时都配置 KoboldCpp。 - 点击
Launch并等待模型加载。
你应该看到类似这样的内容:
Load Model OK: True
Embedded Kobold Lite loaded.
Starting Kobold API on port 5001 at http://localhost:5001/api/
Starting OpenAI Compatible API on port 5001 at http://localhost:5001/v1/
======
Please connect to custom endpoint at http://localhost:5001现在你可以在 SillyTavern 中使用 http://localhost:5001 作为 API URL 连接到 KoboldCpp 并开始聊天。
恭喜!你完成了!
差不多吧。
#
GPU Layers
KoboldCpp 正在工作,但你可以通过确保尽可能多的层卸载到 GPU 来提高性能。你应该在终端中看到类似这样的内容:
llm_load_tensors: offloading 9 repeating layers to GPU
llm_load_tensors: offloaded 9/33 layers to GPU
llm_load_tensors: CPU buffer size = 25215.88 MiB
llm_load_tensors: CUDA0 buffer size = 7043.34 MiB
....................................................................................................
llama_kv_cache_init: CUDA_Host KV buffer size = 1479.19 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 578.81 MiB不要害怕数字;这部分比看起来更容易。CPU buffer size 指的是正在使用的系统 RAM 数量。忽略它。CUDA0 buffer size 指的是正在使用的 GPU VRAM 数量。CUDA_Host KV buffer size 和 CUDA0 KV buffer size 指的是为模型的 context 专门分配的 GPU VRAM 数量。在这种情况下,KoboldCpp 使用了大约 9 GB 的 VRAM。
我有 12 GB 的 VRAM,只有 2 GB 的 VRAM 用于 context,所以我还剩下大约 10 GB 的 VRAM 来加载模型。因为 9 层使用了大约 7 GB 的 VRAM,而 7000 / 9 = 777.77,所以我们可以假设每层使用大约 777.77 MIB 的 VRAM。10,000 MIB / 777.77 = 12.8,所以我会向下取整,从现在开始用这个模型加载 12 层。
现在使用你系统的模型、context 大小和 VRAM 进行自己的计算,并重启 KoboldCpp:
- 如果你很聪明,之前点击了
Save,现在你可以用Load加载你之前的配置。否则,选择你之前选择的相同设置。 - 将
GPU Layers更改为你新的、VRAM 优化的数字(在我的情况下是 12 层)。 - 点击
Save以保存你更新的配置。
你现在应该看到类似这样的内容:
llm_load_tensors: offloading 12 repeating layers to GPU
llm_load_tensors: offloaded 12/33 layers to GPU
llm_load_tensors: CPU buffer size = 25215.88 MiB
llm_load_tensors: CUDA0 buffer size = 9391.12 MiB
....................................................................................................
llama_kv_cache_init: CUDA_Host KV buffer size = 1286.25 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 771.75 MiBKoboldCpp 使用了我 12 GB VRAM 中的大约 11.5 GB。这应该比 KoboldCpp 自动生成的设置表现得更好。
恭喜!你(真的)完成了!
要更深入地了解 KoboldCpp 设置,请查看 Kalomaze 的 Simple Llama + SillyTavern Setup Guide。