#
Image Generatio (图像生成)
使用本地或基于云的 Stable Diffusion、FLUX 或 DALL-E API 生成图像。
自动生成图像作为您消息的回复以获得完全沉浸感,从魔杖菜单或斜杠命令使用聊天历史和角色信息生成图像,或在聊天输入栏中使用 /sd (任何内容) 命令使用您自己的提示词生成图像。
大多数常用的 Stable Diffusion 生成设置都可以在 SillyTavern UI 中自定义。
- 支持
多种图像生成源 ,包括本地和基于云的服务 - 各种
生成模式 用于角色、场景和自定义提示词 斜杠命令 用于在聊天中轻松生成图像交互模式 可根据自然语言请求触发图像生成- 可自定义的提示词模板和
前缀 以保持一致的风格和质量 角色特定提示词前缀 用于定制角色图像风格预设 可快速切换不同的图像生成设置- 灵活的
聊天消息可见性 选项用于生成的图像 - 高级
ComfyUI 集成 用于高度可自定义的工作流程 - 能够
查看所有生成的图像 在角色画廊中 图像滑动 功能可以重新生成图像同时保持相同的提示词- 选项可以
在生成前编辑提示词 和扩展自由模式提示词 - 与 AI
函数调用 集成以自动检测图像生成意图
#
支持的源
#
生成模式
#
如何生成图像
- 使用扩展上下文菜单(魔杖)中的"Image Generation"项。
- 输入带有生成模式表中参数的
/sd (参数)斜杠命令。其他任何内容都会触发"自由模式",让 SD 生成您提示的任何内容。例如:/sd apple tree会生成一棵苹果树的图片。 - 查找聊天消息上下文操作中的画笔图标。这将为所选消息强制使用"Raw Message"模式。
除了原始消息和自由模式之外的每种生成模式都会使用您当前选择的主要生成 API 触发提示词生成,将聊天上下文转换为 SD 提示词。 您可以使用扩展面板中的"SD Prompt Templates"设置抽屉为每种生成模式配置指令模板。
#
/sd 命令使用技巧
#
查看所有生成的图像
要查看角色的所有保存图像(包括其他聊天),请从角色信息面板的"More..."下拉菜单打开画廊,或使用 /show-gallery 斜杠命令。
#
指定负面提示词
在提示词之前使用 negative 命名参数来强制使用特定的负面提示词进行生成。
/sd negative="fries" cute tater farmer holding a tayto in a spud-field
#
包含角色特定前缀
在自由提示词模式下使用特殊的 {{charPrefix}} 宏来包含当前角色的正面和负面提示词前缀(如果已定义)。
/sd {{charPrefix}}, riding a bike
#
抑制聊天消息
您可以通过传递 quiet=true 命名参数来避免将生成的图像发布到聊天中。图像仍会添加到角色画廊中,命令将生成图像的相对 URL,可供其他命令使用。
下面的示例将使用 Markdown 作为用户角色发送生成的图像。
/sd quiet=true me | /send Here's a picture of me: 
#
图像滑动
图像滑动允许在保持相同提示词的同时重新生成图像。如果设置了固定种子,它将为下一次生成随机化。
要循环浏览图像,将鼠标光标悬停(移动设备上点击)在生成的图像上以显示箭头按钮和滑动计数器。点击最新图像上的右箭头将生成一个新图像。
这里的"滑动"只是一个名称,不要尝试实际的滑动手势,因为这会重新生成消息本身,而不是附加的图像。
#
选项
#
生成前编辑提示词
允许在将自动生成的提示词发送到 Stable Diffusion API 之前手动编辑。
#
使用函数工具
使用函数调用自动检测生成图像的意图。
要求:
- 必须使用支持的源配置图像生成。
- 必须使用支持的 Chat Completion API 模型,并在 AI Response 设置中启用函数工具调用。
- 必须在图像生成设置中启用"Use function tool"选项。
- 用户应在聊天消息中表达生成图像的意图,例如"给我发一张猫的图片"。
warning
启用函数工具时,交互模式将不会触发。
#
使用交互模式
允许在回复遵循特殊模式的用户消息时触发图像生成而不是文本:
- 包含以下动词之一:send、mail、imagine、generate、make、create、draw、paint、render
- 后跟以下名词之一(不超过 10 个字符):pic、picture、image、drawing、painting、photo、photograph
- 后跟图像生成的目标主题,可以选择性地在前面加上"of a"或"of this"等短语。
有效请求和捕获主题的示例:
Can you please send me a picture of a cat=>catGenerate a picture of the Eiffel tower=>Eiffel towerLet's draw a painting of Mona Lisa=>Mona Lisa
一些特殊主题会触发预定义的生成模式:
- 'you', 'yourself' => "Yourself"
- 'your face', 'your portrait', 'your selfie' => "Your Face"
- 'me', 'myself' => "Me"
- 'story', 'scenario', 'whole story' => "The Whole Story"
- 'last message' => "The Last Message"
- 'background', 'scene background', 'scene', 'scenery', 'surroundings', 'environment' => "Background"
#
扩展自由模式提示词
使用交互模式或斜杠命令时,通过提示您的主要 API 自动扩展自由模式生成主题描述。
#
对齐自动调整的分辨率
将具有强制纵横比(肖像、背景)的图像生成请求对齐到最接近的已知分辨率,同时尽量保持绝对像素数。请参阅"Resolution"下拉菜单了解可能的选项。
推荐用于 SDXL 模型。
#
通用提示词前缀
在每个生成或自由模式提示词之前添加。通常用于设置图片的整体风格。
示例:best quality, anime lineart。
**专业提示:**使用 {prompt} 宏来指定生成的提示词将被插入的确切位置。
#
负面提示词
您不希望在输出中出现的图像特征。
示例:bad quality, watermark。
#
角色特定提示词前缀
描述当前选择的角色的任何特征。将在通用前缀之后添加。
示例:female, green eyes, brown hair, pink shirt。
您还可以为任何不需要的内容指定负面提示词前缀。它将与通用负面提示词组合。
限制:
- 仅在一对一聊天中有效。不会在群组中使用。
- 不会用于背景和自由模式生成。
如果您想与他人共享前缀,请勾选"Shareable"复选框。这将把它们保存在角色数据中,而不是您的本地设置中。
**专业提示:**如果生成源支持,您也可以在这里使用 LoRAs/embeddings,例如:<lora:DonaldDuck:1>。
#
风格
使用此功能可以快速保存和恢复您喜欢的风格/质量预设,以便稍后使用或在模型之间切换时使用。风格预设包括以下内容:
- 通用提示词前缀
- 负面提示词
您还可以使用 /imagine-style 命令(或 /sd-style 或 /img-style)在风格之间切换。
#
聊天消息可见性
默认情况下,插入聊天的生成图像在主 API 提示词中是隐藏的,但可以针对每个生成发起者("魔杖"图标、斜杠命令、交互模式)单独覆盖。这可以用于通过让角色"认知"图像来使体验更具沉浸感。如果启用了"Send inline images",Chat Completions API 中的多模态模型也可能会"看到"图像。
可以通过更改图像提示词模板下的"Chat Message Template"来自定义文本消息。所有常规宏都可以在此模板中使用,另外还有一个特殊的 {{prompt}} 宏来指定图像提示词将被添加的位置。
#
ComfyUI 配置
ComfyUI 是一个快速且非常灵活的图像生成选项。
如果您熟悉 ComfyUI,简单来说:在 ComfyUI 中制作您的工作流程,以 API 格式下载,然后粘贴到 SillyTavern ComfyUI 工作流程编辑器中。ST 将把您的工作流程提交到 ComfyUI 的 API,您将在聊天中获得一张图像。但是能力越大,责任越大,主要责任是在工作流程 JSON 中插入占位符,以便您可以从 SillyTavern 更改设置。
如果您不熟悉 ComfyUI,您仍然可以使用默认工作流程在 SillyTavern 中生成图像。之后,当您想要更强大的功能时,您可以学习如何使用 ComfyUI...
#
控制
此面板允许您配置和管理 ComfyUI 与 SillyTavern 的集成。
在 ComfyUI URL 输入字段中输入您的 ComfyUI 服务器的 URL。默认值是 http://127.0.0.1:8188。
如果您使用的是 SwarmUI,托管 ComfyUI 服务器的默认端口是 7821,比 SwarmUI 的默认端口高 20。
输入 URL 后,选择 Connect 以验证并建立连接。ComfyUI 服务器必须可以从 SillyTavern 主机访问。
#
工作流程管理
从下拉菜单中选择 ComfyUI 工作流程。提供了两个默认工作流程:
- Default_Comfy_Workflow.json:支持最常见图像生成设置的基本文本到图像工作流程。
- Char_Avatar_Comfy_Workflow.json:使用角色头像加上提示词生成图像的示例图像到图像工作流程。
使用以下按钮管理您的工作流程:
- Open workflow editor 查看和修改所选工作流程。
- Create new workflow 创建具有自定义名称的新工作流程。
- Delete workflow 删除所选工作流程。
#
工作流程编辑器
ComfyUI 工作流程编辑器允许您查看和修改用于 SillyTavern 的 ComfyUI 工作流程。
编辑器的主要组件是一个大型文本区域,您可以在其中插入或编辑 JSON 格式的 ComfyUI 工作流程。
要将 ComfyUI 工作流程添加到编辑器,请按照以下步骤操作:
- 在 ComfyUI 设置中启用"Dev Mode"。
- 使用 ComfyUI 中的"Save (API Format)"选项下载 JSON 数据。
- 在 SillyTavern 中创建新工作流程并打开编辑器。
- 将下载的 JSON 数据粘贴到文本区域中。
info Tips
您可以添加 API-格式 JSON 文件直接到 data/default-user/user/workflows 目录在您的 SillyTavern 安装。这将节省步骤 3 和 4。
保留原始 JSON 文件。如果您需要再次在 ComfyUI 中打开工作流程以进行更改,编辑原始文件比带有所有占位符的文件要方便得多。
#
占位符
编辑器提供了一系列预定义的占位符,可以在您的工作流 JSON 中使用。这些占位符在 SillyTavern 执行工作流时会被替换为动态值。
标记为 ✅ 的占位符存在于您的工作流 JSON 中。标记为 ❌ 的占位符不存在于您的工作流 JSON 中。您可以根据需要将这些占位符添加到您的工作流 JSON 中。您不需要添加所有占位符,只需添加您的工作流使用并且您想要动态替换的占位符。
#
提示词
%prompt% 和 %negative_prompt% 占位符用于将图像生成提示词插入到工作流中。它们包含由 SillyTavern 生成的最终提示词,包括为您选择的 /sd 模式生成的提示词、通用提示词前缀、负面提示词和角色特定提示词前缀。
例如,您可能在 ComfyUI 中使用类似"森林精灵"的提示词测试了您的工作流。要在 SillyTavern 中使用此工作流,您可以用 %prompt% 占位符替换"森林精灵"提示词:
{
"class_type": "CLIPTextEncode",
"inputs": {
"clip": ["4", 1],
"text": "%prompt%"
}
}{
"class_type": "CLIPTextEncode",
"inputs": {
"clip": ["4", 1],
"text": "forest elf"
}
}请注意,占位符用双引号括起来。这对于 JSON 格式很重要,并且是 SillyTavern 的占位符替换系统所必需的。即使对于数字,您也必须在模板 JSON 中使用双引号。
有时提示词(或其他值)不会出现在您期望的位置。如果节点对于工作流在 API 模式下运行不是必需的,ComfyUI 将从工作流的 API 版本中删除这些节点。
例如,此工作流使用 LoRA 标签加载器节点 和提示词原语,以便工作流在 UI 模式下更清晰:
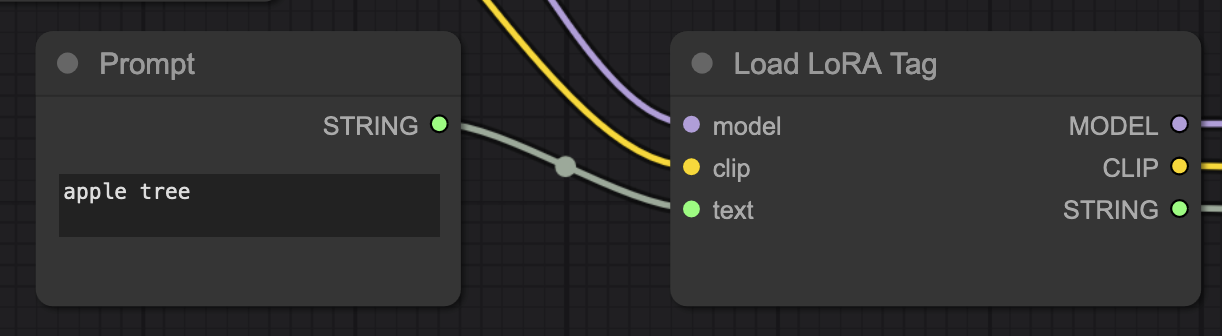
提示词原语节点将从工作流的 API 版本中删除,因此您需要在 LoraTagLoader 节点中插入占位符。在工作流中找到文本"apple tree"并将其替换为 %prompt% 占位符:
{
"inputs": {
"text": "%prompt%",
"model": ["112", 0],
"clip": ["112", 1]
},
"class_type": "LoraTagLoader",
"_meta": {"title": "Load LoRA Tag"}
}{
"inputs": {
"text": "apple tree",
"model": ["112", 0],
"clip": ["112", 1]
},
"class_type": "LoraTagLoader",
"_meta": {"title": "Load LoRA Tag"}
}在某些情况下,您可能需要在工作流 JSON 中进行多次替换,即使提示词在 UI 中只出现一次。
#
模型
%model% 占位符将插入图像生成设置中选定模型的值。
默认文本到图像工作流中的一个示例:
{
"class_type": "CheckpointLoaderSimple",
"inputs": {
"ckpt_name": "%model%"
}
}{
"class_type": "CheckpointLoaderSimple",
"inputs": {
"ckpt_name": "sd15.safetensors"
}
}要加载 GGUF 量化的 UNet,请在工作流中使用 UNet Loader (GGUF) 节点,
在 SillyTavern 模型下拉菜单中选择一个 GGUF 模型,并在节点设置中像这样使用 %model% 占位符:
{
"inputs": {
"unet_name": "%model%"
},
"class_type": "UnetLoaderGGUF",
"_meta": {
"title": "Unet Loader (GGUF)"
}
}{
"inputs": {
"unet_name": "flux1-dev-Q4_0.gguf"
},
"class_type": "UnetLoaderGGUF",
"_meta": {
"title": "Unet Loader (GGUF)"
}
}info 如果您在 ComfyUI 中有除通常的 SD 检查点之外的模型类型
Stable Diffusion 检查点、SD UNet 和 GGUF 量化的 UNet 都出现在模型下拉菜单中。 一种类型的模型将无法与期望另一种类型的工作流/加载器节点一起使用。 如果您在 ST 中选择不兼容的模型类型,ComfyUI 将报告加载器节点有问题。
#
头像图像
使用 %user_avatar% 和 %char_avatar% 占位符在工作流中包含用户和角色头像。这些占位符在执行工作流时会被替换为头像的 PNG 数据。图像数据以 base64 格式编码,因此您必须在工作流中对其进行解码。此任务的一个流行选择是 Load image (Base64) 节点。
在此示例中,角色头像使用 Load Image (Base64) 节点加载。它还使用 Image Resize 节点将图像重新缩放到图像生成设置中指定的任何大小:
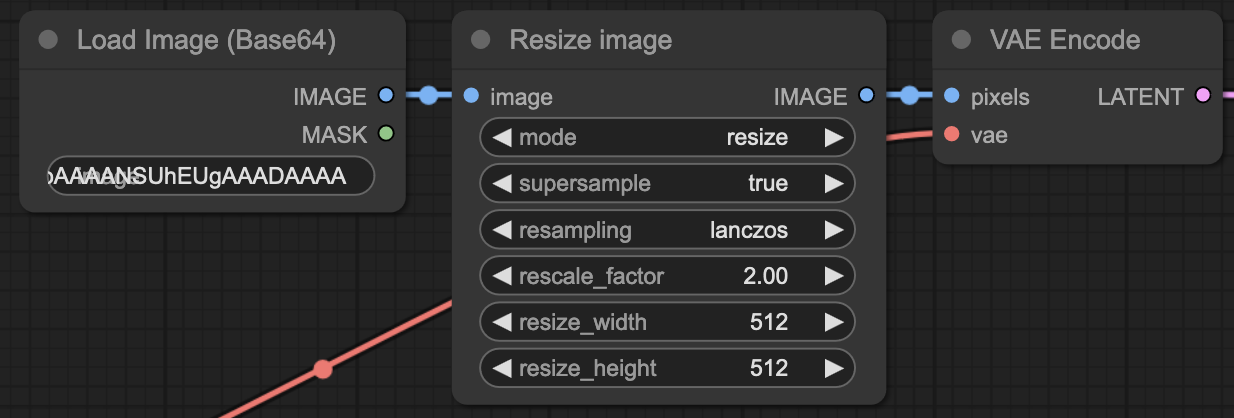
将 %char_avatar%、%width% 和 %height% 占位符插入到 Load Image (Base64) 和 Image Resize 节点的 JSON 中:
{
"97": {
"inputs": {
"image": "%char_avatar%"
},
"class_type": "ETN_LoadImageBase64",
"_meta": {"title": "Load Image (Base64)"}
},
"98": {
"inputs": {
"mode": "resize",
"resize_width": "%width%",
"resize_height": "%height%",
"image": ["97", 0]
},
"class_type": "Image Resize",
"_meta": {"title": "Resize image"}
}
}要获取 base64 编码的图像字符串以在 ComfyUI 中测试您的工作流,请使用任何将图像转换为 base64 字符串的在线工具。 这是一个您可以用于初始测试的示例字符串:sd-comfy-base64-test-string.txt。
#
其他占位符
大多数其他占位符使用图像生成设置中相应控件的值,或您使用 /sd 命令指定的值:
%vae%,但大多数 SD 模型都包含 VAE,因此默认工作流不使用此占位符。将其与自定义工作流一起使用以加载 VAE 以及 UNet,覆盖默认 VAE 等。%sampler%%scheduler%%steps%%scale%%width%%height%%denoise%:对于示例图像到图像工作流,在约 0.5(对源图像几乎没有明显更改)和 1.0(完全不同的图像,就像没有使用源图像一样)之间改变去噪量。默认文本到图像工作流不使用,因为对于文本到图像使用除 1.0 之外的值没有意义。%clip_skip%:默认工作流不使用,但可用于自定义工作流。
如果您指定了种子值,%seed% 占位符将插入控件中的种子值。如果您将种子设置为 -1,SillyTavern 将为 %seed% 中的每个图像生成一个新的随机种子。
#
自定义占位符
您可以向工作流添加自定义占位符:
- 在预定义占位符下方查找"自定义"部分。
- 单击"+"按钮添加新的自定义占位符。
- 在
find字段中输入占位符的名称。 - 在
replace字段中输入要替换占位符的值。
自定义占位符将出现在预定义占位符下方的单独列表中。
例如,您可以使用自定义占位符替换默认工作流中已保存图像文件名的"SillyTavern"前缀。添加一个新的自定义占位符,将 find 设置为 filename_prefix,将 replace 设置为 ServiceTesnor。将新的 %filename_prefix% 占位符插入到您的工作流 JSON 中。现在,您可以通过更改自定义占位符的值,将 SillyTavern 中的文件名前缀更改为 ServiceTesnor。
{
"class_type": "SaveImage",
"inputs": {
"filename_prefix": "%filename_prefix%",
"images": ["8", 0]
}
}{
"class_type": "SaveImage",
"inputs": {
"filename_prefix": "SillyTavern",
"images": ["8", 0]
}
}
#
Comfy 技巧
阅读此页面上的所有常规信息,以便您熟悉图像生成选项。诸如可切换样式和通用提示词前缀之类的选项,与 ComfyUI 工作流的完全灵活性相结合,使您能够创建各种各样的图像生成设置。
#
加载 LoRA
使用 LoRA 标签加载器节点(例如 Load LoRA Tag)加载提示词中指定的任何 LoRA。
现在,您可以使用 <lora:CroissantStyle:0.8> 之类的标签将任意数量的 LoRA 添加到您的提示词中,它们将被加载到您的工作流中。
这也将使在
#
从样式或斜杠命令设置工作流值
您可以在自定义占位符值中使用宏。作为一个实际示例, 假设您有时想生成没有背景的图像,并且您希望可以使用 斜杠命令或图像样式切换此功能。以下是您可以执行的操作:
- 制作一个 ComfyUI 工作流,根据输入的值删除图像背景或不删除。
- 使用自定义占位符设置该输入的值,但使用
{{getvar::remove_background}}作为替换值 - 现在您可以在生成图像之前使用
/setvar key=remove_background true或/setvar key=remove_background false设置remove_background的值 - 工作流将使用您设置的值来确定是否删除背景
- 制作一个带有通用提示词前缀
{{setvar::remove_background::true}}的图像样式"无背景" - 在生成图像之前使用样式控件或
/imagine-style 无背景将remove_background的值设置为true